InformationWeightTransformer¶
The information weight transformer is designed to improve the embeddings given by a simple Ngram Vectorizer by taking into account the amount of information that each token provides. It plays a similar role to the Term Frequency - Inverse Document Frequency transform for weighting count vectors, but by performing a calculation which is grounded in Bayesian inference and information theory.
It is inspired by the paper An information-theoretic perspective of tf–idf measures by A. Aizawa (https://doi.org/10.1016/S0306-4573(02)00021-3)
Example: Distinctive Ingredients from Regional Cuisines¶
Consider a dataset of recipes, labelled by what regional cuisine they came from, and defined by a list of the ingredients used in the recipe.
[1]:
import numpy as np
import pandas as pd
from vectorizers.transformers import InformationWeightTransformer
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
import matplotlib.pyplot as plt
from pathlib import Path
import json
from zipfile import ZipFile
[2]:
path_recipes = Path("data/recipes.zip")
with ZipFile(path_recipes) as file_data:
data = pd.DataFrame(json.loads(file_data.read("train.json")))
with pd.option_context("max_colWidth", 120):
display(data)
| id | cuisine | ingredients | |
|---|---|---|---|
| 0 | 10259 | greek | [romaine lettuce, black olives, grape tomatoes, garlic, pepper, purple onion, seasoning, garbanzo beans, feta cheese... |
| 1 | 25693 | southern_us | [plain flour, ground pepper, salt, tomatoes, ground black pepper, thyme, eggs, green tomatoes, yellow corn meal, mil... |
| 2 | 20130 | filipino | [eggs, pepper, salt, mayonaise, cooking oil, green chilies, grilled chicken breasts, garlic powder, yellow onion, so... |
| 3 | 22213 | indian | [water, vegetable oil, wheat, salt] |
| 4 | 13162 | indian | [black pepper, shallots, cornflour, cayenne pepper, onions, garlic paste, milk, butter, salt, lemon juice, water, ch... |
| ... | ... | ... | ... |
| 39769 | 29109 | irish | [light brown sugar, granulated sugar, butter, warm water, large eggs, all-purpose flour, whole wheat flour, cooking ... |
| 39770 | 11462 | italian | [KRAFT Zesty Italian Dressing, purple onion, broccoli florets, rotini, pitted black olives, Kraft Grated Parmesan Ch... |
| 39771 | 2238 | irish | [eggs, citrus fruit, raisins, sourdough starter, flour, hot tea, sugar, ground nutmeg, salt, ground cinnamon, milk, ... |
| 39772 | 41882 | chinese | [boneless chicken skinless thigh, minced garlic, steamed white rice, baking powder, corn starch, dark soy sauce, kos... |
| 39773 | 2362 | mexican | [green chile, jalapeno chilies, onions, ground black pepper, salt, chopped cilantro fresh, green bell pepper, garlic... |
39774 rows × 3 columns
We can count-vectorize the ingredients, obtaining a vector 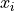 for each recipe, and we can get a count-vector
for each recipe, and we can get a count-vector 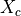 for each type of cuisine by summing together the vectors corresponding to all recipes in the cuisine
for each type of cuisine by summing together the vectors corresponding to all recipes in the cuisine  .
.
Let us take the convention that is a row vector; then it’s 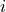 th entry represents the number of times that ingredient was used in cuisine ’s recipes. We can find the largest entries of to get the most common ingredients in a given cuisine:
th entry represents the number of times that ingredient was used in cuisine ’s recipes. We can find the largest entries of to get the most common ingredients in a given cuisine:
[3]:
tokens = []
for i, idno in enumerate(data['id'].to_list()):
tokens_i = ''.join(x.replace(" ","_").replace("-","_")+' ' for x in list(data['ingredients'].iloc[i]))
tokens.append(tokens_i)
vectorizer = CountVectorizer()
vectors = vectorizer.fit_transform(tokens)
[4]:
cuisine_array = np.array(data['cuisine'].to_list())
cuisines = np.unique(cuisine_array)
n_cuisines = np.size(cuisines)
cookbook_vectors = np.zeros((n_cuisines, np.shape(vectors)[1]))
keywords_freq = []
for k, cuisine in enumerate(cuisines):
idx = (cuisine_array == cuisine).nonzero()
cookbook_vectors[k] = np.sum(vectors[idx], axis=0)
sort_ = np.argsort(cookbook_vectors[k])
cuisine_str = ''
for idx in sort_[-3:]:
word=vectorizer.get_feature_names_out()[idx]
cuisine_str += word.capitalize().replace("_"," ") + ", "
keywords_freq.append(cuisine_str)
df = pd.DataFrame()
df['Cuisine'] = [x.capitalize() for x in cuisines]
df['Most Frequent'] = keywords_freq
df
[4]:
| Cuisine | Most Frequent | |
|---|---|---|
| 0 | Brazilian | Olive oil, Onions, Salt, |
| 1 | British | Butter, All purpose flour, Salt, |
| 2 | Cajun_creole | Garlic, Onions, Salt, |
| 3 | Chinese | Salt, Sesame oil, Soy sauce, |
| 4 | Filipino | Water, Garlic, Salt, |
| 5 | French | All purpose flour, Sugar, Salt, |
| 6 | Greek | Dried oregano, Olive oil, Salt, |
| 7 | Indian | Garam masala, Onions, Salt, |
| 8 | Irish | Butter, All purpose flour, Salt, |
| 9 | Italian | Garlic cloves, Olive oil, Salt, |
| 10 | Jamaican | Water, Onions, Salt, |
| 11 | Japanese | Mirin, Salt, Soy sauce, |
| 12 | Korean | Garlic, Sesame oil, Soy sauce, |
| 13 | Mexican | Ground cumin, Onions, Salt, |
| 14 | Moroccan | Ground cumin, Olive oil, Salt, |
| 15 | Russian | Onions, Sugar, Salt, |
| 16 | Southern_us | All purpose flour, Butter, Salt, |
| 17 | Spanish | Garlic cloves, Olive oil, Salt, |
| 18 | Thai | Salt, Garlic, Fish sauce, |
| 19 | Vietnamese | Salt, Sugar, Fish sauce, |
These most frequent words are not very good at distinguishing the cuisines, because there are some ingredients that are just too universally common. For example, salt appears in the top 3 for every cuisine except Korean!
To obtain more distinctive words, we can try to weight the words according to their relative frequencies in each document. This is the working principle behind Term Frequency - Inverse Document Frequency (TF-IDF) weighting. Let’s try TF-IDF and Information Weighting and see what distinguishing words we obtain:
[5]:
## Information Weighting:
IWT = InformationWeightTransformer()
iwt_vectors = IWT.fit_transform(vectors,y=data['cuisine'].to_list())
cookbook_vectors_iwt = np.zeros((n_cuisines, np.shape(vectors)[1]))
keywords_iwt = []
for k, cuisine in enumerate(cuisines):
idx = (cuisine_array == cuisine).nonzero()
cookbook_vectors_iwt[k] = np.sum(iwt_vectors[idx], axis=0)
for k, cuisine in enumerate(cuisines):
sort_ = np.argsort(cookbook_vectors_iwt[k])
cuisine_str = ''
for idx in sort_[-3:]:
word=vectorizer.get_feature_names_out()[idx]
cuisine_str += word.capitalize().replace("_"," ") + ", "
keywords_iwt.append(cuisine_str)
## TF-IDF Weighting:
TFIDF = TfidfTransformer()
tfidf_vectors = TFIDF.fit_transform(vectors)
cookbook_vectors_tfidf= np.zeros((n_cuisines, np.shape(vectors)[1]))
for k, cuisine in enumerate(cuisines):
idx = (cuisine_array == cuisine).nonzero()
cookbook_vectors_tfidf[k] = np.sum(tfidf_vectors[idx], axis=0)
keywords_tfidf = []
for k, cuisine in enumerate(cuisines):
sort_ = np.argsort(cookbook_vectors_tfidf[k])
cuisine_str = ''
for idx in sort_[-3:]:
word=vectorizer.get_feature_names_out()[idx]
cuisine_str += word.capitalize().replace("_"," ") + ", "
keywords_tfidf.append(cuisine_str)
df['TF-IDF'] = keywords_tfidf
df['Info Weight'] = keywords_iwt
df
[5]:
| Cuisine | Most Frequent | TF-IDF | Info Weight | |
|---|---|---|---|---|
| 0 | Brazilian | Olive oil, Onions, Salt, | Sweetened condensed milk, Lime, Cachaca, | Chocolate sprinkles, Açai, Cachaca, |
| 1 | British | Butter, All purpose flour, Salt, | Salt, All purpose flour, Milk, | Beef drippings, Suet, Stilton cheese, |
| 2 | Cajun_creole | Garlic, Onions, Salt, | Onions, Green bell pepper, Cajun seasoning, | Creole seasoning, Andouille sausage, Cajun sea... |
| 3 | Chinese | Salt, Sesame oil, Soy sauce, | Corn starch, Sesame oil, Soy sauce, | Shaoxing wine, Soy sauce, Sesame oil, |
| 4 | Filipino | Water, Garlic, Salt, | Water, Garlic, Soy sauce, | Calamansi juice, Fish sauce, Soy sauce, |
| 5 | French | All purpose flour, Sugar, Salt, | All purpose flour, Salt, Unsalted butter, | Grated gruyère cheese, Cognac, Gruyere cheese, |
| 6 | Greek | Dried oregano, Olive oil, Salt, | Feta cheese, Olive oil, Feta cheese crumbles, | Greek seasoning, Feta cheese, Feta cheese crum... |
| 7 | Indian | Garam masala, Onions, Salt, | Ground turmeric, Salt, Garam masala, | Cumin seed, Ground turmeric, Garam masala, |
| 8 | Irish | Butter, All purpose flour, Salt, | Salt, All purpose flour, Butter, | Irish cream liqueur, Guinness beer, Irish whis... |
| 9 | Italian | Garlic cloves, Olive oil, Salt, | Salt, Grated parmesan cheese, Olive oil, | Shredded mozzarella cheese, Ricotta cheese, Gr... |
| 10 | Jamaican | Water, Onions, Salt, | Dried thyme, Salt, Ground allspice, | Ground allspice, Jamaican jerk season, Scotch ... |
| 11 | Japanese | Mirin, Salt, Soy sauce, | Sake, Soy sauce, Mirin, | Dashi, Sake, Mirin, |
| 12 | Korean | Garlic, Sesame oil, Soy sauce, | Sesame seeds, Soy sauce, Sesame oil, | Sesame oil, Kimchi, Gochujang base, |
| 13 | Mexican | Ground cumin, Onions, Salt, | Chili powder, Jalapeno chilies, Salt, | Flour tortillas, Salsa, Corn tortillas, |
| 14 | Moroccan | Ground cumin, Olive oil, Salt, | Ground cinnamon, Olive oil, Ground cumin, | Ras el hanout, Preserved lemon, Couscous, |
| 15 | Russian | Onions, Sugar, Salt, | Sour cream, Sugar, Salt, | Dill, Fresh dill, Beets, |
| 16 | Southern_us | All purpose flour, Butter, Salt, | All purpose flour, Butter, Salt, | Bourbon whiskey, Grits, Buttermilk, |
| 17 | Spanish | Garlic cloves, Olive oil, Salt, | Salt, Extra virgin olive oil, Olive oil, | Serrano ham, Saffron threads, Spanish chorizo, |
| 18 | Thai | Salt, Garlic, Fish sauce, | Lemongrass, Coconut milk, Fish sauce, | Thai red curry paste, Lemongrass, Fish sauce, |
| 19 | Vietnamese | Salt, Sugar, Fish sauce, | Garlic, Sugar, Fish sauce, | Beansprouts, Lemongrass, Fish sauce, |
Using the advanced eyeball test, we can see that the TF-IDF and IWT weighted words are much more distinctive of the various cuisines. However the TF-IDF weighting still leaves a lot of redundancy, such as salt still showing up for half of the cuisines. The information weight transform, on the other hand, has distinguished the cuisines much more, and we see some well-known associations like Kimchi in Korean cuisine or Feta in Greek cuisine.
Theoretical Explanation¶
What is the Information Weight Transform actually doing? It is weighting each column (word) by the information that an observation of that column conveys relative to the baseline probability. Suppose you have an array of vectors 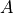 so that
so that ![A[d]](_images/math/b87697464b4c5410635076082f10a1f5099ed928.png) is a row vector recording the word counts of document
is a row vector recording the word counts of document 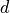 . First, a baseline probability distribution over the set of documents is computed by dividing the length of each document by the total number of words in the corpus.
. First, a baseline probability distribution over the set of documents is computed by dividing the length of each document by the total number of words in the corpus.
![P_0(d) = \left(\sum_{i=0}^{N} A[d]_i\right / \left(\sum_{i=0}^{N}\sum_{d} A[d]_i\right)](_images/math/0d1d0c58924144224074f959527d95b02bdf3dc8.png)
If one picks a random word 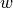 from the corpus, the baseline probability distribution
from the corpus, the baseline probability distribution 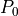 is a Bayesian prior for which document the word came from. However, if we look at the word , we can update to a posterior distribution
is a Bayesian prior for which document the word came from. However, if we look at the word , we can update to a posterior distribution 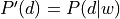 determined by the count data. The information gain from an observation of the word is the relative entropy, or Kullback-Leibler divergence,
determined by the count data. The information gain from an observation of the word is the relative entropy, or Kullback-Leibler divergence,
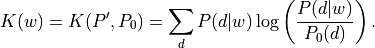
The information weight transform assigns a weight of 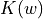 to the column of the array corresponding to the count of word .
to the column of the array corresponding to the count of word .
For example, let us first plot the baseline probability for the recipe data. We’ll again aggregate along the ‘Cuisine’ axis.
[6]:
baseline_counts = np.squeeze(np.array(cookbook_vectors.sum(axis=1)))
baseline_probabilities = baseline_counts / baseline_counts.sum()
N_data = np.shape(cookbook_vectors)[0]
prior_strength = 0.1
word_index = vectorizer.vocabulary_['sake']
observed_counts = cookbook_vectors[:,word_index]
observed_norm = observed_counts.sum() + prior_strength
observed_probabilities = (
observed_counts + prior_strength * baseline_probabilities
) / observed_norm
fig, (ax1,ax2) = plt.subplots(1,2)
fig.set_size_inches(10, 5)
ax1.bar(np.arange(N_data), baseline_probabilities, tick_label=cuisines)
plt.sca(ax1)
plt.title("Prior distribution")
plt.xticks(rotation='vertical')
ax2.bar(np.arange(N_data), observed_probabilities, tick_label=cuisines,color='g')
plt.sca(ax2)
plt.title("Posterior after observing 'sake'")
plt.xticks(rotation='vertical')
plt.show()
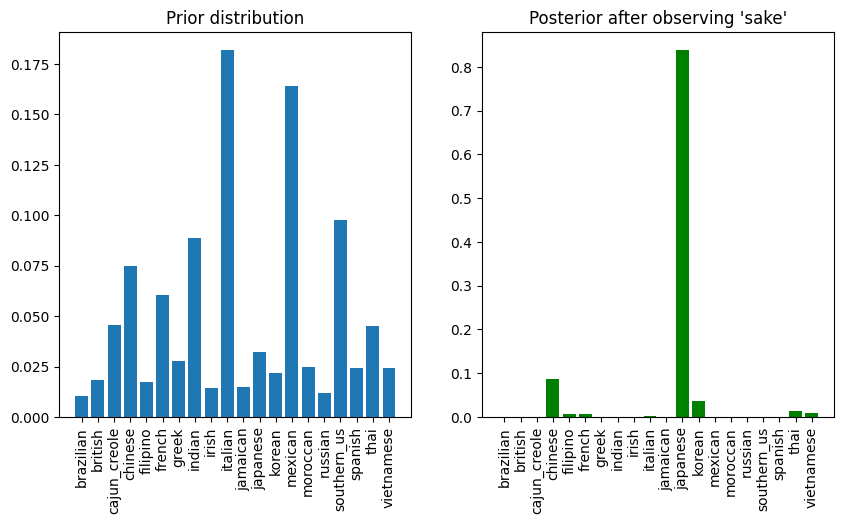
Computing the information gain of this observation, and handling the change in support due to zero observations, we obtain the information weight for sake:
[7]:
observed_zero_constant = (prior_strength / observed_norm) * np.log(
prior_strength / observed_norm
)
result = 0.0
for i, cuisine in enumerate(cuisines):
if observed_probabilities[i] > 0.0:
result += observed_probabilities[i] * np.log(
observed_probabilities[i] / baseline_probabilities[i]
)
else:
result += baseline_probabilities[i] * observed_zero_constant
print("The information weight of 'sake' is",result)
The information weight of 'sake' is 2.7023532028001647
One final note of comparison: Suppose that a) all documents have the same length, and b) if a word 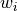 appears in a document, it does so a constant number
appears in a document, it does so a constant number 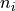 of times. In this situation, TF-IDF and IWT agree exactly.
of times. In this situation, TF-IDF and IWT agree exactly.
In this sense, one can think of the Information Weight Transform as a TF-IDF which accounts for variability in document lengths and the information provided by relative frequency of a word in different documents.
Example: Wine Reviews¶
This example will demonstrate using extra parameters for when the data is not exactly counts. The wine reviews data set, as reviewed for the CategoricalColumnTransformer, is an excellent example. It consists of 150,930 wine reviews along with the winery that made the wine, it’s country, province, regions, wine variety and a few other variables. This plethora of categorical values will allow us to demonstrate some subtleties in the InformationWeightTransfromer.
[8]:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
from sklearn.datasets import fetch_openml
import umap
from vectorizers.transformers import InformationWeightTransformer
For simplicity, we are only going to keep a few varieties and regions, and drop all the text column associated with each review. Furthermore, to demonstrate a boolean column (where the value can be True of False), we store wether the price of the bottle is above the median price in the restricted dataset.
[9]:
data_openml = fetch_openml('wine_reviews', version=1)
data = pd.DataFrame(data_openml.data)
# Cut down dataset by only keeping a few well known varieties
keep_varieties = ['Cabernet Franc', "Syrah", "Merlot", "Pinot Gris", "Riesling", "Chardonnay"]
keep_regions = ['Central Coast', 'Columbia Valley', 'Napa', 'North Coast', 'Sonoma']
data = data[(data["variety"].isin(keep_varieties)) & (data["region_2"].isin(keep_regions))]
data["above_median_price"] = (data["price"] >= data["price"].median())
data = data[['variety', 'winery', "region_2", "designation", "above_median_price",]].drop_duplicates()
print(len(data))
data.describe(include='all').T
5267
[9]:
| count | unique | top | freq | |
|---|---|---|---|---|
| variety | 5267 | 6 | Chardonnay | 2191 |
| winery | 5267 | 1867 | Chateau Ste. Michelle | 33 |
| region_2 | 5267 | 5 | Central Coast | 1784 |
| designation | 3364 | 2115 | Estate | 181 |
| above_median_price | 5267 | 2 | True | 2770 |
[10]:
fig, axs = plt.subplots(1, 2, figsize=(12, 6))
counts = data["variety"].value_counts()
axs[0].bar(counts.index.to_list(), counts.values)
axs[0].tick_params(axis='x', rotation=45)
axs[0].set_title("Count of each Variety in the Data")
counts = data["region_2"].value_counts()
axs[1].bar(counts.index.to_list(), counts.values)
axs[1].tick_params(axis='x', rotation=45)
axs[1].set_title("Count of each Region in the Data")
[10]:
Text(0.5, 1.0, 'Count of each Region in the Data')
Next, we can convert this dataframe into a standard count matrix using One Hot Encodings. Each answer to our categorical variables gets it’s own column, and the row has a 1 (True) if the value of that categorical matches the column.
[11]:
ohe = OneHotEncoder()
cat_data = ohe.fit_transform(data[["region_2", "variety", "designation", "above_median_price"]])
cat_data
[11]:
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 21068 stored elements and shape (5267, 2129)>
We could directly apply the information weight transform to this matrix, but we can leverage the fact that we know several columns have been encoded from a single categorical variable. The way we pass this information to the InformationWeightTransformer is through the column_groups keyword argument. The column groups are stored in an array with length equal to the number of columns in the count matrix, and the value of the array at each index denotes the group that the column belongs to.
When we transform the matrix, the baseline (or prior) distributions is computed for each group separately.
[12]:
column_groups = np.empty(cat_data.shape[1], dtype="int32")
next_id = 0
next_index = 0
for cat in ohe.categories_:
column_groups[next_index:next_index+len(cat)] = next_id
next_index += len(cat)
next_id += 1
column_groups
[12]:
array([0, 0, 0, ..., 2, 3, 3], shape=(2129,), dtype=int32)
[13]:
iwt = InformationWeightTransformer()
iwt_data = iwt.fit_transform(cat_data, column_groups=column_groups)
iwt_data
[13]:
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 21068 stored elements and shape (5267, 2129)>
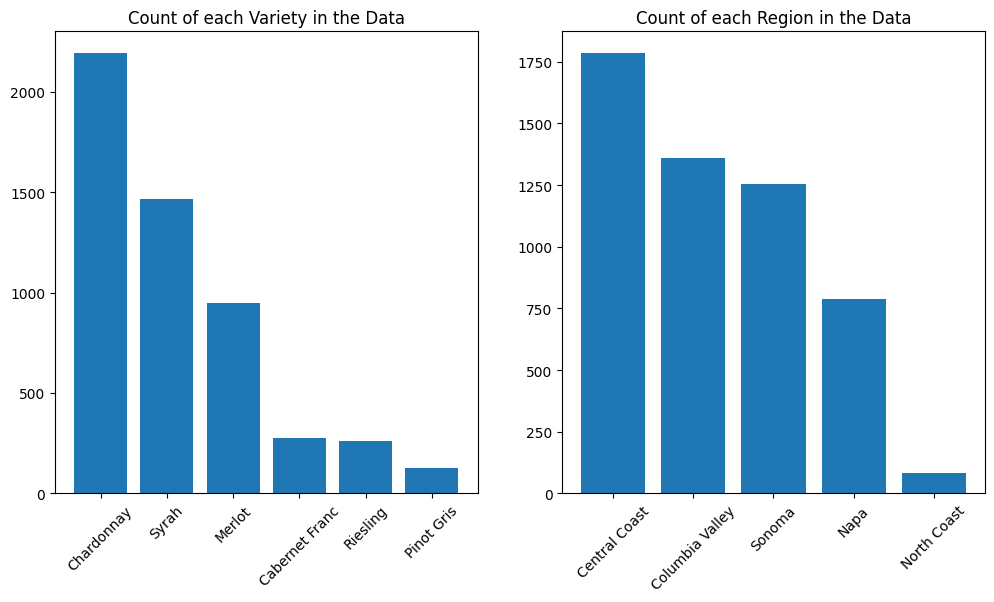
And finally we can use our favorite dimension reduction technique to draw a pretty picture. Both plots below are the same vectors, the only difference is on the left points are colored by variety, whereas on the right they are colored by region.
[14]:
low = umap.UMAP(metric='hellinger', random_state=17, init="pca").fit_transform(iwt_data)
/Users/ryandewolfe/miniforge3/envs/acme4/lib/python3.13/site-packages/umap/umap_.py:1952: UserWarning: n_jobs value 1 overridden to 1 by setting random_state. Use no seed for parallelism.
warn(
/Users/ryandewolfe/miniforge3/envs/acme4/lib/python3.13/site-packages/numba/np/ufunc/dufunc.py:290: RuntimeWarning: invalid value encountered in sparse_correct_alternative_hellinger
return super().__call__(*args, **kws)
[15]:
fig, axs = plt.subplots(1, 2, figsize=(14, 5))
label = "variety"
label_dict = {variety:i for i,variety in enumerate(data[label].unique())}
label_id = np.array([label_dict[i] for i in data[label]])
scatter = axs[0].scatter(low[:, 0], low[:, 1], c=label_id, alpha=0.5)
axs[0].set_aspect("equal")
handles, labels = scatter.legend_elements()
axs[0].legend(handles, list(label_dict.keys()), title="Variety", bbox_to_anchor=(1.01, 1), loc='upper left')
axs[0].set_axis_off()
label = "region_2"
label_dict = {variety:i for i,variety in enumerate(data[label].unique())}
label_id = np.array([label_dict[i] for i in data[label]])
scatter = axs[1].scatter(low[:, 0], low[:, 1], c=label_id, alpha=0.5)
axs[1].set_aspect("equal")
handles, labels = scatter.legend_elements()
axs[1].legend(handles, list(label_dict.keys()), title="Region", bbox_to_anchor=(1.01, 1), loc='upper left')
axs[1].set_axis_off()
Parameters¶
One benefit of the information weight transform is it’s lack of hyperparameters that need to be chosen. The InformationWeightTransformer class only has three keyword arguments:
approximate_prior- Whether to approximate weights based on the Bayesian prior or perform exact computations. Approximations are much faster especially for very large or very sparse datasets.
prior_strength - How strongly to weight the prior when doing a Bayesian update to derive a model based on observed counts of a column.
y - If supervised target labels are available, these can be used to define distributions over the target classes rather than over rows, allowing weights to be supervised and target based. If None then unsupervised weighting is used.